드라이빙 테이블이란?
===================
TABLE에 대한 JOIN시 먼저 ACCESS되서 ACCESS PATH를 주도하는
TABLE을 DRIVING TABLE이라 한다.
DRIVING TABLE로 결정되는 것은 INDEX의 존재 및 우선순위 혹은
FROM절에서의 TABLE지정순서에 영향을 받으며 어느 TABLE이 먼저
ACCESS되느냐에 따라 속도의 차이가 크게 날 수 있으므로 매우
중요하다. 기본적으로 대상 TABLE의 행 중 작업대상이 되는 행의 수 가
적은 쪽이 먼저 ACCESS되어야 전체 일 양이 줄어든다. Driving table의
결정 규칙은 다음과 같다.
. JOIN 되는 컬럼의 한쪽에만 INDEX가 있는 경우는 INDEX가 지정된
TABLE이 DRIVING TABLE이 된다.
WHERE emp.deptno = dept.deptno 문장에서 dept.deptno에 index가 있는
경우는 Dept 테이블이드라이빙 테이블이 된다.
WHERE emp.deptno = dept.deptno 문장에서 emp.deptno에 index가 있는
경우는 Emp 테이블이 드라이빙 테이블이 된다.
WHERE emp.deptno = dept.deptno
AND emp.empno=7788
AND loc like 'Ca%'
deptno, empno컬럼이 조합해서 인덱스 . loc와 deptno컬럼이 조합해서
인덱스가 이루어져 있는경우 Dept 테이블이 드라이빙 테이블이 되고
만일 인덱스가 empno와deptno컬럼이 조합해서 인덱스,
deptno와loc컬럼이 조합해서 인덱스로 구성되어 있으면 Emp 테이블이
드라이빙 테이블이 된다..조건절에 두 테이블 조인 조건외에 다른 비교
조건이 지정된 경우 INDEX의 우선순위에 따라 먼저 수행된는 테이블이
드라이빙 테이블이 된다.
WHERE emp.deptno = dept.deptno
AND emp.empno = 1166
AND dept.loc like 'da%'
emp.deptno, dept.deptno, empno,loc에 인덱스가 있는 경우는 empno와
loc중 우선순위가 높은 empno 인덱스를 먼저 사용하여 검색한다. 만일
이때 loc 라는 인덱스를 사용하고 싶으면 emp.empno=1166을
rtrim(empno)=1166 로 바꾸어 사용하면 empno의 인덱스 사용을 억제할수
있다.
더욱 이해를 돕기위해 다음의 예를 살펴보자.
DEPT.DEPTNO 컬럼에 Unique 인덱스
LOC 컬럼에 Unique 인덱스
EMP.JOB 과 EMP.ENAME 컬럼을 조합한 Unique Index
EMP.DEPTNO 에 인덱스 가 있다고 가정하자
WHERE d.deptno = e.deptno AND job='PRESIDENT'
AND ename='KING' AND loc='NEW YORK'
AND dname='ACCOUNTING' 의 문장 수행을 위한 내부적인 수행은 다음과 같다.
만일 DEPT 테이블이 드라이빙 테이블이라면
loc='NEW YORK'
dname = 'ACCOUNTING'
만일 EMP 테이블이 드라이빙 테이블이라면
job= 'PRESIDENT'
ename =' KING' 이다.
즉 DEPT 테이블이 unique 인덱스 를 사용하고 EMP 테이블은 컬럼이
조합된 unique 인덱스를 사용하므로 우선순위가 높은 DEPT 테이블이
DRIVING TABLE이 된다.
2010-10-05
튜닝의 도구 – SQL*TRACE와 TKPROF
튜닝의 도구 – SQL*TRACE와 TKPROF Oracle의 SQL*TRACE는 사용자가 실행 한 SQL문에 대해 구문분석(Parsing), 실행(execute), 추출(fetch) 부분으로 나누어 각 단계에서 걸리는 Overhead와 시간 등의 통계 정보를 일정한 형태로 저장 합니다. EXPALIN PLAN에서 제공하는 정보와 더블어 CPU/IO의 필요량, 실행계획의 각 단계에서의 레코드 개수등의 정보도 확인 가능 합니다. EXPLAIN PLAN 명령어와 함께 자주 사용되는 튜닝의 도구 입니다. SQL*TRACE나 TKPROF를 실행 했을 때의 결과는 이해하기가 쉽지 않지만 강력한 튜닝의 도구 입니다. SQL*TRACE에 의해 분석되는 결과는 바이너리 형태로 운영체제의 파일 시스템에 생성 됩니다. 물론 바이너리 이므로 결과를 직접 눈으로 보면 이해가 되지 않지만 TKPROF 유틸리티를 이용하여 텍스트 파일 형태로 변환 시켜 확인이 가능 합니다. SQL*TRACE의 결과는 데이터베이스 전체 또는 특정 세션에 대해 적용 할 수 있는데 데이터베이스 전체에 트레이스를 적용하면 실제 Application 수행에 추가적인 부하를 가져오므로 특별한 경우를 제외하고 전체 데이터베이스 시스템에 TRACE를 거는 것은 삼가 해야 합니다. 대부분은 특정 세션에 대해서만 부분적으로 활성화 하여 사용 합니다. SQL*TRACE의 사용 SQL TRACE를 사용하기 전에 몇 가지 설정이 필요한데 먼저 초기파일에서 USER_DUMP_DEST 파라미터를 확인해야 합니다. 이 매개변수는 TRACE를 실행 할 때 생성되는 파일의 위치를 설정 하는 것입니다. 또한 시간 정보를 TRACE 항목에 추가할려면 TIMED_STATISTICS 항목을 TRUE로 해야 하거나 SQL*Plus등에서는 alter session set timed_statistics=true 라고 해주어야 합니다. 아래에 자세히 확인 하도록 합니다. TIMED_STATISTICS 시간 통계 정보에 대해 수집여부를 결정, 기본값은 false 세션레벨에서는 alter session set timed_statistics=true라고 하면 됩니다. MAX_DUMP_FILE_SIZE TRACE 의 결과로 생기는 바이너리 파일의 최대 사이즈를 단위는 블록 입니다. 기본값은 500 블록 입니다. 또한 세션 레벨에서 다음과 같이 지정 가능 합니다. Alter session set max_dump_file_size = 800(800개의 시스템 블록) USER_DUMP_DEST TRACE의 결과로 생기는 바이너리 파일의 위치를 지정 합니다. 세션레벨에서는 alter session set user_dump_dest = “C:\oracle\admin\wink\udump” 등으로 지정 합니다. 위 의 세개의 파라미터를 init.ora 파일에 지정하였다면 SQL*TRACE의 시작을 전체 데이터베이스에서 할건지 세션 레벨에서 할건지를 정할 수가 있습니다. 인스턴스 레벨에서 할려면 init.ora 파일에서 SQL_TRACE 항목을 TRUE로 설정하면 되구요 세션 레벨에서 할려면 alter session set sql_trace = true 라고 하면 됩니다. 자 이제 실습을 위해 위의 3개의 매개변수를 init.ora 에 설정토록 합니다. MAX_DUMP_SIZE = 800 TIMED_STATISTICS = TRUE USER_DUMP_DEST = C:\oracle\admin\wink\udump 다음을 따라 하도록 합니다. SQL> conn / as sysdba 연결되었습니다. SQL> shutdown immediate 데이터베이스가 닫혔습니다. 데이터베이스가 마운트 해제되었습니다. ORACLE 인스턴스가 종료되었습니다. SQL> startup open ORACLE 인스턴스가 시작되었습니다. Total System Global Area 135338868 bytes Fixed Size 453492 bytes Variable Size 109051904 bytes Database Buffers 25165824 bytes Redo Buffers 667648 bytes 데이터베이스가 마운트되었습니다. 데이터베이스가 열렸습니다. SQL>conn scott/tiger SQL> alter session set sql_trace=true; 세션이 변경되었습니다. SQL> select job,avg(sal) from emp 2 group by job 3 having avg(sal) > (select avg(sal) from emp 4 where job = 'SALESMAN'); JOB AVG(SAL) --------- ---------- ANALYST 3000 MANAGER 2758.33333 PRESIDENT 5000 session에서 trace를 중지 SQL> alter session set sql_trace=false; SQL*Plus를 종료하고 c:\oracle\admin\wink\udump에 가보면 trc 파일이 생겼을 것 입니다. 저의 경우 DB SID가 wink이므로 wink_ora_3316.trc 와 같은 파일이 생겼습니다. TKPROF를 이용하여 TRACE파일을 텍스트 파일로 변경 하기 TKPROF Utility를 이용하면 매우 유용한 분석 정보를 얻을 수 있습니다. 즉 TKPROF의 결과 파일은 트레이스가 실행되는 동안 프로세스에 의해 데이터베이스에서 실행된 작업에 대한 요약 정보 입니다. 텍 스트 파일의 내용을 보면 PARSE, EXECUTION, FETCH시 작업을 실행 한 횟수, CPU 사용 시간, 검색된 행이 무엇인지, SQL이 수행된 총 소요시간, DISK IO 블록 수, 조건을 만족하는 전체 행의 수, 수행된 SQL문이 사용한 SGA 영역의 크기, SQL문장의 실행 계획, 해당 세션에서 작업했던 전체 작업에 대한 CPU, 메모리, 블록의 크기 등의 정보를 확인 할 수 있습니다. SQL문을 해석하기 위해서는 아래의 단계가 필요 합니다. 파싱(parse) SQL문을 실행 계획으로 번역 하는 것을 말합니다. 해당 SQL을 실행 하는데 필요한 적절한 권한, 컬럼이 있는지, 참조된 객체에 관한 확인 등의 작업이 이루어지게 됩니다. 실행(execution) 오라클에 의해 SQL문을 실제 실행 한 것을 말합니다. 추출/인출(fetch) 쿼리에 의해 추출된 레코드를 이여기 합니다. Select 문에서만 이용 됩니다. 다음은 TKPROF의 통계 정보 컬럼 입니다. Count : 분석, 실행, 추출을 몇번 했는지를 나타 냅니다. CPU : 분석, 실행, 추출에 대한 CPU 처리 시간(CURSOR를 공유하면 분석단계의 처리 시간은 0 입니다.) Elapsed : 분석, 실행, 추출 처리 단계별로 처리된 소요 시간 Disk : 테이블의 데이터를 읽기 위해 데이터 파일로부터 읽어 들인 블록 수 Query : SELECT로 데이터를 읽어 올 때 이미 다른 사용자에 의해 같은 데이터가 사용 되었다면 그 블록에서 데이터를 가져옵니다. Current : 메모리에 저장된 데이터를 가지고 오기 위해 읽은 버퍼의 블록 수(update, insert, delete 후 select 했을 때) TKPROF를 실행하기 위한 문법 Explain = 사용자계정/패스워드(명시된 사용자에 대해 EXPLAIN PLAN 실행) Print = n (트레이스 파일내의 분석된 SQL문의 수를 n 만큼만 제한할 때 이용) Record = 파일명(트레이스 파일내에 분석된 SQL문을 지정한 파일에 저장) Sort=option(트레이스 파일내에 분석된 SQL문을 지정한 옵션에 의해 정렬) Sys=[NO](트레이스 파일내에 생성된 SQL 문장 중에 오라클 서버가 내부적인 작업을 위해 실행한 SQL문장을 출력 시 포함 할건지를 결정) Table=스키마.테이블명(실행 계획을 지정한 테이블에 저장) 이전의 SQL*TRACE에 의해 생긴 바이너리 파일을 TKPROF를 이용하여 분석을 해보도록 하겠습니다. 명령프롬픝에서 다음과 같이 실행 합니다.(TRACE 파일이 만들어진 곳에서 실행) C:\oracle\admin\wink\udump>tkprof wink_ora_3316.trc sql1.tkp sys=no explain=scot t/tiger TKPROF: Release 9.2.0.1.0 - Production on 목 Dec 16 01:33:23 2004 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. 다음은 sql1.tkp 파일의 내용 입니다. TKPROF: Release 9.2.0.1.0 - Production on 목 Dec 16 01:33:23 2004 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Trace file: wink_ora_3316.trc Sort options: default ******************************************************************************** count = number of times OCI procedure was executed cpu = cpu time in seconds executing elapsed = elapsed time in seconds executing disk = number of physical reads of buffers from disk query = number of buffers gotten for consistent read current = number of buffers gotten in current mode (usually for update) rows = number of rows processed by the fetch or execute call ******************************************************************************** alter session set sql_trace=true call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 0 0.00 0.00 0 0 0 0 Execute 1 0.00 0.00 0 0 0 0 Fetch 0 0.00 0.00 0 0 0 0 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 1 0.00 0.00 0 0 0 0 Misses in library cache during parse: 0 Optimizer goal: CHOOSE Parsing user id: 59 (SCOTT) ******************************************************************************** 아래는 사용자가 실행한 SQL 문장 입니다. select job,avg(sal) from emp group by job having avg(sal) > (select avg(sal) from emp where job = 'SALESMAN') call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.00 0.00 0 0 0 0 Execute 1 0.00 0.00 0 0 0 0 Fetch 2 0.00 0.00 0 6 0 3 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 4 0.00 0.01 0 6 0 3 Misses in library cache during parse: 1 이 값이 0이라는 의미는 실행한 SQL문이 이전에 실행 된적이 없었음을 나타 냅니다. Optimizer goal: CHOOSE 옵티마이저 모드 입니다. Parsing user id: 59 (SCOTT) Rows Row Source Operation ------- --------------------------------------------------- 3 FILTER 5 SORT GROUP BY 14 TABLE ACCESS FULL EMP 1 SORT AGGREGATE 4 TABLE ACCESS FULL EMP Rows Execution Plan ------- --------------------------------------------------- 0 SELECT STATEMENT GOAL: CHOOSE 3 FILTER 5 SORT (GROUP BY) 14 TABLE ACCESS GOAL: ANALYZED (FULL) OF 'EMP' 1 SORT (AGGREGATE) 4 TABLE ACCESS GOAL: ANALYZED (FULL) OF 'EMP' ******************************************************************************** alter session set sql_trace=false call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.00 0.00 0 0 0 0 Execute 1 0.01 0.00 0 0 0 0 Fetch 0 0.00 0.00 0 0 0 0 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 2 0.01 0.00 0 0 0 0 Misses in library cache during parse: 0 Optimizer goal: CHOOSE Parsing user id: 59 (SCOTT) ******************************************************************************** 아래의 TOTAL은 전체 작업 결과에 대한 분석 결과 입니다. OVERALL TOTALS FOR ALL NON-RECURSIVE STATEMENTS call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 2 0.00 0.00 0 0 0 0 Execute 3 0.01 0.00 0 0 0 0 Fetch 2 0.00 0.00 0 6 0 3 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 7 0.01 0.01 0 6 0 3 Misses in library cache during parse: 1 OVERALL TOTALS FOR ALL RECURSIVE STATEMENTS call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.00 0.00 0 0 0 0 Execute 1 0.00 0.00 0 0 0 0 Fetch 1 0.01 0.00 0 3 0 1 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 3 0.01 0.00 0 3 0 1 Misses in library cache during parse: 0 3 user SQL statements in session. 1 internal SQL statements in session. 4 SQL statements in session. 1 statement EXPLAINed in this session. ******************************************************************************** Trace file: wink_ora_3316.trc Trace file compatibility: 9.00.01 Sort options: default 1 session in tracefile. 3 user SQL statements in trace file. 1 internal SQL statements in trace file. 4 SQL statements in trace file. 4 unique SQL statements in trace file. 1 SQL statements EXPLAINed using schema: SCOTT.prof$plan_table Default table was used. Table was created. Table was dropped. 54 lines in trace file. |
Oracle Optimizer
Oracle Optimizer의 원리 이해 및 SQL & 애플리케이션의 튜닝(하):
오라클의 튜닝 기법의 100% 활용
지난 회에서는 튜닝에 들어가기 위해 먼저 Oracle Optimizer의 원리와 특징에 대해서 설명했다.
이번 회에서는 조인 메소드별 특징과 플랜 보는 법을 이해하고, 실제 오라클에서 제공하는 튜닝 기법들을 활용해 보도록 하자.
이번 회에서는 조인 메소드별 특징과 플랜 보는 법을 이해하고, 실제 오라클에서 제공하는 튜닝 기법들을 활용해 보도록 하자.
숲을 보는 튜닝
튜닝에는 정답이 없다. 즉 튜닝은 시스템의 특징이나 업무의 특징들을 정확히 이해하고, 그 상황에 맞게 문제의 원인을 확인하고, 문제의 원인을 해결하기 위한 최적의 튜닝 방법을 찾아야 한다는 것이다.
튜 닝의 기본 목표는 자원을 상황에 맞게 효율적으로 사용해서 원하는 결과값을 원하는 시간 내에 받아보는 것이다. 병렬 기능을 많이 사용한다고 해서 항상 좋은 결과가 나오는 것은 아니다. 또한 시스템의 자원은 한정되어 있다는 것을 항상 명심해야 한다. 하나의 애플리케이션이 한정된 시스템 자원을 병렬 기능을 사용해서 독점한다면, 다른 애플리케이션들은 상대적으로 피해를 보게 되는 것이다. 즉 튜닝은 하나의 애플리케이션을 위한 것이 아니라 모든 애플리케이션이 조화롭게 운영될 수 있도록 하여야 한다는것이다.
이런 입장에서 필자는 나무를 보지 말고 숲을 보라고 항상 강조한다. 즉 단위 SQL 문장의 플랜(plan) 튜닝도 중요하지만, 전체적인 조화를 이루는 SQL 문장의 유형 및 구조적인 문제 등이 더 중요하다는 것이다. 업무 시작 이후에 구조적인 문제를 해결하려면 상당한 인적, 시간적 자원을 소모해야 하지만, SQL 문장의 플랜적인 튜닝은 해당SQL 문장의 튜닝결과를 적용하는 것으로, SQL 문장의구조적, 유형적 튜닝에 비해 상대적으로 적은 비용이 들 것이다. 그래서 튜닝 작업을 이런 측면에서 바라보도록 항상 노력하여야 할 것이다.
조인 메소드별 특징
오라클의 조인 메소드는 Nested Loop Join(NLJ), Sort Merge Join(SMJ), Hash Join(HJ)의 3가지가 있다. 이들 3가지 조인 메소드로 여러 조인 타입 (Basic(natural) Join, Outer Join, Semi Join, Anti Join 등)을 지원하게 된다. Oracle Optimizer는 최적화 단계에서 이들 조인 메소드들 중 조인에 대한Selectivity와Cardinality의 계산에 의해 가장 효율적인 것을 선택하게된다. 단 RBO(Rule Base Optimizer)에서는 인위적인 힌트(USE_HASH)를 주지않고서는 Hash Join은 전혀 고려하지 않는다. 힌트를 준 것 자체가 이미 RBO가 아니라 CBO(Cost Base Optimizer)로 동작되는 것이다.
조인 을 확인할 때 조인 메소드 뿐만 아니라 조인 순서 또한 중요하다. 먼저 액세스 되는 쪽을 ‘드라이빙테이블(Driving Table) ’ 이라고 하며, 나중에 액세스되는 테이블을‘이너 테이블(Inner Table)’이라고 한다. Hash Join 에서는‘Build Table’과‘Probing Table’이라는 용어로 사용된다. SQL 문장에서 튜닝을 잘 하기 위해서는 조인 메소드별 특징을 정확히 이해하고 플랜을 통해 처리되는 과정을 그려볼 수 있어야 한다.
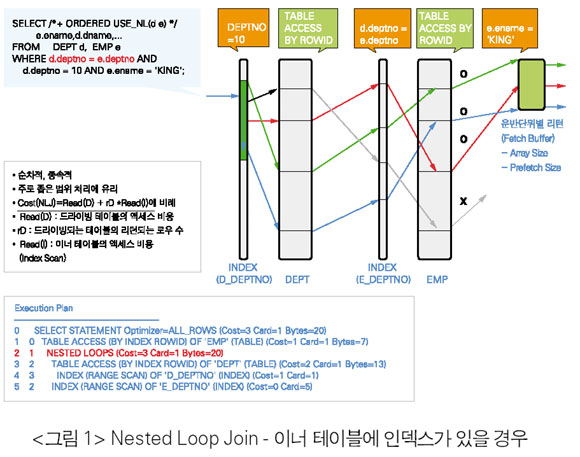
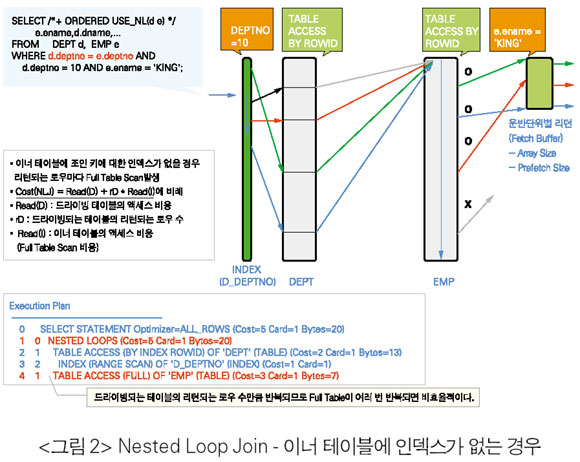
Nested Loop Join(NLJ)
• NLJ는 순차적인 처리로Fetch의 운반단위(Array Size, Prefetch Size)마다 결과 로우(row)를리턴 받을 수 있다.
• 첫 번째 로우를 받는 시간은 빠르나, 전체 결과 로우를 받는 데까지 걸리는 시096 ORACLE KOREA MAGAZINE 간은 느리다. 즉 첫 번째 로우를 받을 준비가 되어 있는 단계까지를 실행시간으로 볼 때 실행시간은 빠르나 Fetch 시간은 느리다.
• NLJ는 메모리가 필요 없는 조인이다. 그러므로 추가적인 메모리 비용이 필요없다.
• NLJ는 드라이빙 테이블에서 많은 로우들이 필터링되어 이너 테이블로 찾아 들어가는 부분을 줄여야 하므로 드라이빙 순서가 중요하다.
• 이너 테이블은 드라이빙 테이블의 리턴되는 모든 로우들에 대해서 반복 실행하므로 액세스 효율이 좋아야 한다. 즉 대부분의 경우 이너 테이블은 인덱스가 있어야 한다. 또한 인덱스의 효율이 좋아야 한다. 이너 테이블이 작더라도 액세스 횟수가 많다면 인덱스가 있어야 한다. 인덱스의 효율이 좋지 않아 전체의 Index Range Scan과 같은 경우는 최악의 조건이다.
• NLJ는 주로 인덱스 위주의 싱글 블록 I/O의랜덤I/O 위주이므로OLTP에서 적은 데이타 범위 처리에 주로 사용된다. 즉 전체의 15% 이상의 경우는 Full Table Scan을 이용한 Sort Merge 또는 Hash Join을 이용한다.
• NLJ도 드라이빙 테이블이 Full Table Scan에 병렬로 처리되면 이너 테이블도 병렬로 종속적으로 처리된다.
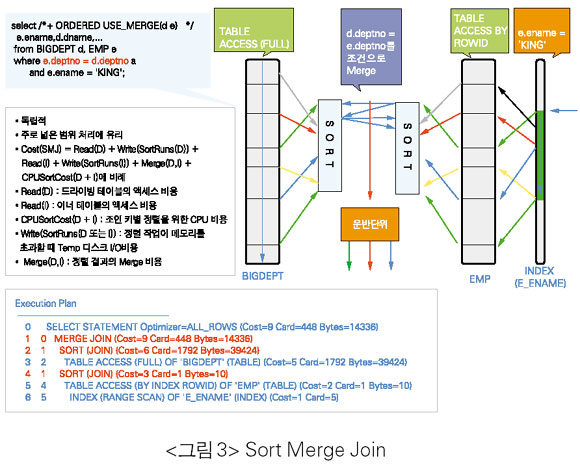
Sort Merge Join(SMJ)
• 전체 로우를 리턴 받는 시간이 빠르다. 즉 첫 번째 로우를 리턴 받을 준비까지의 시간은 느리지만, 준비가 된 상태에서의 Fetch 시간은 빠르다(메모리에서 리턴하므로). 이는 대상 로우들(Where 조건에 의해 필터된 로우들만 정렬)을 가지고 정렬 작업(모든 로우들을 조인 키로 정렬)을 하기 전까지는 어떠한 로우도 리턴할 수 없기 때문이다.
• NLJ와같이 드라이빙 테이블의 리턴되는 로우 수와 이너 테이블의 액세스 패턴에 의에 액세스 효율이 좌우되지 않으며, 조인 테이블 간에 자신의 처리범위로만 처리량을 결정하므로 독립적이다.
• 추가적인 정렬 메모리(SORT_AREA_SIZE) 비용이 필요하다. 메모리가 부족하면 TEMP 테이블스페이스에 정렬 중간단계(Sort Runs)를 기록하게 되므로 추가적인 디스크 I/O비용이 발생할 수 있다.
• 정렬 메모리에 위치하는 대상은 조인 키뿐만 아니라 Select List도 포함하므로 불필요한 Select List는 제거해야 한다.
• 정렬 작업의 CPU 사용에 대한 오버헤드가 있다. 그러므로 많은 로우들과 전체적으로 Select List의 사이즈의 합이 큰 테이블의 조인에는 문제가 있다. 즉 디스크 정렬을 피할 수가 없으며, 정렬에CPU 비용이 많이 든다.
• 디스크 정렬만 발생하지 않는다면 넓은 범위 처리에 유리하다.
• 디스크 정렬을 피할 수 없는 경우라면(Batch Job, Create index,...)
SORT_AREA_SIZE , SORT_MULTIBLOCK_READ_COUNT를SQL마다 세션 레벨에 할당해서 사용하도록 한다(WORKAREA_SIZE_POLICY가 Manual일 경우나 Oracle9i Database 이전 버전에서). 또한TEMP 테이블 스페이스의 Extent Size도 충분히 크게 주도록 한다.
ALTER SESSION SET SORT_AREA_SIZE= 104857600; ALTER SESSION SET SORT_AREA_RETAINED_SIZE= 104857600; (같이 준다) ALTER SESSION SET SORT_MULTIBLOCK_READ_COUNT=128; • 정렬 메모리의 크기는 (= Target rows×(total selected column’s bytes)×2) 이상 설정하되, PGA의 메모리 한계로 인해 테스트를 통해 PGA Memory Allocation Error가 발생하지 않는 범위 내에서 설정하도록 한다. 필요시 10032 Trace를 이용해 점검한다.
ALTER SESSION SET EVENTS ‘10032 TRACE NAME CONTEXT FOREVER’;
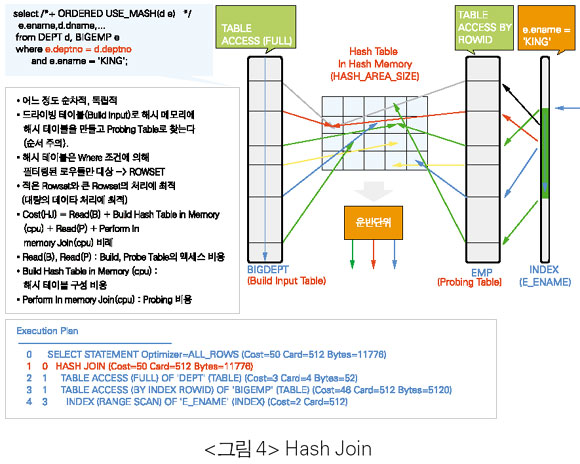
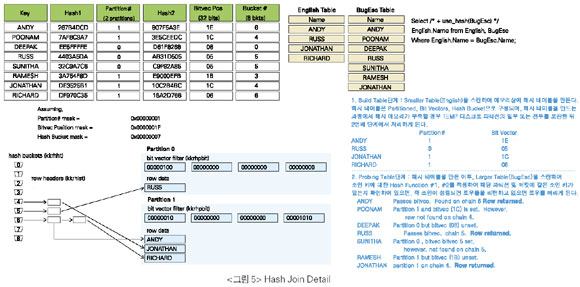
Hash Join(HJ)
• Hash Join은 두 개의 조인 테이블 중Small Rowset(Where 조건에 의해 필터링된 로우 수가 작은 테이블)을 가지고 HASH_AREA_SIZE에 지정된 메모리 내에 해시 테이블을 만든다.
• 해시 테이블을 만든 이후부터는NLJ의 장점인 순차적인 처리 형태이다. 그러므로NLJ과SMJ의 장점을 가지고 있다.
• Hash Join은 Basic Join( ‘=’)만 가능하다.
• NLJ와같이 드라이빙 테이블의 리턴되는 로우 수와 이너테이블의 액세스 패턴에 의에 액세스의 효율이 좌우되지 않으며, 조인 테이블 간에 자신의 처리 범위로만 처리량을 결정하므로 독립적이다.
• SMJ의 단점인 많은 로우들의 처리 또는 전체적으로 Select List의 사이즈의 합이 큰 테이블의 조인시 정렬 작업의 CPU 사용에 대한 오버헤드 및 디스크 정렬과 같은 문제점은 없다. 그러므로 최소한SMJ보다는 우수하다.
• 한 테이블은 작은 Rowset 사이즈(리턴되는 로우 수와 Select List 기준), 다른 한 테이블은 아주 큰 사이즈의 조인에 유리하다. 이러한 경우는 반드시 작은 사이즈를 가지고 해시 테이블을 만들어야 한다. 단, Hash Join은 순서가 매우 중요하다는 점에 주의하는데, 작은 Rowset으로 해시 테이블을 만들어야 하기 때문이다.
• 힌트를 잘못 주어서 Big Rowset이 리턴되는 테이블부터 드라이빙된다면(Build Table), HASH_AREA_SIZE의 메모리 부족으로 TEMP 디스크 I/O가 발생한다. 그러므로 힌트를 줄 경우 반드시 드라이빙 순서를 정확히 주어야 한다.
• 디스크 I/O를 피할 수 없는 경우라면, HASH_AREA_SIZE(default : =SORT_AREA_SIZE×2)를 SQL마다 세션 레벨에 할당해서 사용하도록 한다(WORKAREA_SIZE_POLICY가 Manual일 경우이거나 Oracle9i Database 이전 버전에서). 또한TEMP 테이블스페이스의 Extent Size도 충분히 크게 주도록 한다. HASH_MULTIBLOCK_IO_COUNT는 옵티마이저에게 자동 조정하도록 설정하지 않는다.
ALTER SESSION SET HASH_AREA_SIZE= 104857600; • 해시 메모리의 사이즈는 (= Small Table의 Target rows×(total selected column’s bytes)×1.5) 이상 설정하되, PGA의 메모리의 한계로 인해 테스트를 통해 PGA Memory Allocation Error가 발생하지 않는 범위 내에서 설정하도록 한다. 필요시 10104 Trace를 이용해 점검한다.
ALTER SESSION SET EVENTS ‘10104 TRACE NAME CONTEXT FOREVER’;
SQL 튜닝시 고려사항
SQL 튜닝시에 고려해야 할 점을 정리하면, 다음과 같다.
• 가능한 힌트는 사용하지 않는다. 힌트를 많이 구사한 애플리케이션들은 지난호에서 설명했던 것과 같이 기준(파라미터 및 통계정보)이 잘못 설정된 경우가 많다. 힌트는 최후에 어쩔 수 없는 경우에 사용하도록 한다.
- 1차적으로 플랜이 원하는 경우가 아닐 경우 통계정보 및 Init.ora의 파라미터 값들을 확인해 본다.
[USER|ALL|DBA]_TABLES,[USER|ALL|DBA]_INDEXES,[USER|ALL| DBA]_TAB_COLUMNS 등의 딕셔너리 정보 확인, 최종 분석 시간, 블록 수, 로우 수, 칼럼의 Distinct 값, 인덱스의 Clustering Factor, Sample Size 등을 확인하다. 이들 값들이 현실 데이타와 비슷한지 확인한다. 통계정보가 없거나 너무 오래됐거나 샘플링 사이즈가 너무 작은 경우, 현실 데이타와 다를 수 있다. 이러한 경우는 통계정보를 다시 생성한다.
- 칼럼에 대한 통계정보(히스토그램)는 안 돌리는 것을 원칙으로 한다. 그러나 편향된 데이타 분포도를 가지고 있다면 히스토그램을 운영한다. 또한 이들 칼럼에 대한 Where 절의 사용되는 값들은 바인드 변수를 사용하지 않도록 한다. 히스토그램을 사용하는 곳에는 상수(literal) 값을 사용하여야 플랜이 효과적으로 풀린다.
- 힌트를 지정할 경우는 가능한 타이트하게 주도록 한다. 그렇지 않을 경우 향후 플랜이 변경될 가능성이 많기 때문이다.
예> /*+ USE_NL(a b) */ ==> /*+ ORDERED USE_NL(a b) .... */ - 힌트는 힌트의 의미를 정확히 이해하고 합당한 힌트를 주도록 한다. 어설픈 힌트는 오히려 역효과가 발생되는 경우가 많다.
• 통계정보는 운영중에 직접 돌리지 않는다.
- 집중적인 운영시기에 통계정보 수집을 위한 실행은 Library Cache Contention을 유발하며, 관련 SQL 및 PL/SQL들을 Invalid시켜 성능저하 및 문제의 원인이 되기도 한다.
- 저녁시간의 한가한 시간을 이용해서 돌린다(특히 시스템의 집중 사용시기 등에 유의).
• WORKAREA_SIZE_POLICY=AUTO이면*_AREA_SIZE는 이용하지 않으며, 설정해봐야 의미가 없다. 즉 옵티마이저는 *_AREA_SIZE에 의해 플랜을 결정하지 않는다.
• 튜닝시 플랜적인 튜닝뿐만 아니라 구조적인 튜닝에도 집중한다.
- Execution이 높은 것은 과다한 Loop Query가 아닌지 검토한다. Loop Query의 보완, 최적화가 필요하다.
- 일회성(상수를 사용) 비공유 SQL, 특히 집중적으로 실행되는 Literal SQL은 바인드 변수 기법을 사용한다.
- 파싱(parsing)을 줄이는 방법으로 Java의‘Statement Cache’, PRO*C의 RELEASE_CURSOR=NO 등 프그래밍 언어의 효과적인 기법들을 사용한다.
- Array Processing 기능을 사용한다. 기본적으로 거의 대부분의 DB 접속 방식에서 이들 기법들을 제공하고 있으며, 코딩상의 특별한 처리 없이 PREFETCH 기능이 이와 같은 기능이며, 애플리케이션 개발시 특별한 구현 작업 없이 옵션 설정만으로 가능하다(ODBC, JDBC, OO4O, ADO, PRO*C 등).
- PL/SQL의 Bulk Binding/Bulk Collecting 기능을 이용한다.
- Aggregate Function 등 향상되고 효과적인 여러 질의 기능을 활용한다.
• 튜닝시 플랜은 상수로 테스트하지만, 실제로 바인드 변수로 운영되는 경우 플랜이 다를 수 있다. 프로그램에 바인드 변수로 되어 있다면 바인드 변수로 플랜을 확인해 봐야 한다.
• 기타 다음 사항도 고려한다.
- Hash Join을 사용할 경우 드라이빙 순서, Rowset을 고려하여 사용한다.
- SQL 문장에서 반드시 필요한 칼럼만 선택한다. 불필요한 칼럼들은 정렬, 해시 작업에서 메모리에 로딩해야 하므로 TEMP 디스크 I/O의 원인이 되기도 한다.
- Chaining % 비율을 항상 검토하고 Row Chaining 비율이 높은 테이블에 대해서는 칼럼의 데이타 타입 조정 및 블록의 PCTFREE 등을 늘리도록 한다. 테이블의 구조적인 문제 또는 업무적인 형태를 고려하여 Reorg를 하도록 한다(CTAS, MOVE, Exp/Imp 등 이용).
• 평균 로우 길이와 블록당 로우 수도 항상 주의 깊게 관찰하여 문제점이 없는지 검토한다 (통계정보이용 DBA_TABLES.NUM_ROWS/DBA_TABLES.BLOCKS). 블록당 로우가 적은 경우는DELETE가 많이 된 경우이므로, Full Table Scan이 자주 발생된다면 Reorg 대상이 될 수 있다. 그러나RAC 환경에서는 블록 경합을 줄이기 위해 인위적으로PCTFREE를 키워 블록당 로우 수를 적게 가져가는 경우도 있다.
• Hash Join과 Sort Merge Join시TEMP쪽에 I/O가 발생하지 않도록 한다.
• PRO*C 애플리케이션일 경우, 바인드 변수의 사용여부, RELEASE_CURSOR=NO, PREFETCH=1000(batch), PREFETCH=100(OLTP)를 권장한다.
Execution Plan 보기
Execution Plan이란 옵티마이저가 질의 최적화 단계에서RBO 또는CBO에 의해 결정해낸 최적의 액세스 경로 정보를 가지고QEP Generator가 만들어낸 실행 계획이다. 이Execution Plan은SQL 문장이 실행될 때 필요한 모든 정보를 포함하고 있다.
• 액세스 경로 : 어떠한 방법으로 데이타에 접근할 것인가? (Index Scan, Index Fast Full Scan, Full Table Scan 등)
• 조인 메소드 : 어떤 조인 메소드를 사용할 것인가?
• 조인 순서 : 어떠한 조인의 순서로 풀릴 것인가?
• 조인 메소드 : 어떤 조인 메소드를 사용할 것인가?
• 조인 순서 : 어떠한 조인의 순서로 풀릴 것인가?
다음과 같은 Execution Plan을 가정하자.

플랜에서 나오는 각 라인을‘로우 소스(Row Source)’라고 한다. 플랜을 보면서 처리 순서를 판단하는 것은 간단하다. 플랜은 트리 형태로 되어 있으며, 자신보다 하위 레벨이 있으면 하위 레벨부터, 같은 레벨이라면 위(상)의 로우소스부터 실행 된다.
위 플랜의‘Optimizer=CHOOSE’에서알수있듯이해당SQL 문장은 옵티마이저 모드가 CHOOSE에서 플랜이 만들어진 것이다. 또한 플랜에서 ‘Cost=’의 항목이 나오면CBO로 풀렸다는 것이다. RBO인지 CBO인지의 판단은 옵티마이저 모드의 항목으로 판단하는 것이 아니라 ‘Cost=’로 판단한다는 것에 주의하자.
위 플랜에서 2개의 테이블 DEPT와 EMP 테이블 각각의 액세스 경로를 확인할 수 있다. 모두 인덱스를 사용하고 있는 것이다. 또한 조인메소드로는 Nested Loop Join이 사용되었다. 조인 순서는 자신보다 하위 레벨이 있으면 하위 레벨부터, 같은 레벨이라면 위의 로우 소스부터 실행된다는 법칙을 적용해보면, ID를기준으로4 -> 3 -> 5 -> 2 -> 1 -> 0의 순서로 처리 된다. 단 조인메소드가 Nested Loop이기 때문에 3에서 리턴되는 로우 수만큼 다음 단계가 반복된다. 그러므로 조인 순서는 DEPT -> EMP 순으로 Nested Loop로 처리될 것 이라는 것을 알 수 있다.
또한‘Card=5’는Computed Cardinality를나타내며, 몇 건의 로우가 리턴될 것인지를 CBO가 통계정보를 이용해서 계산해낸 값이다.
‘Bytes=250’은 리턴 될 로우들의 바이트를 나타내므로 5 로우에 250바이트 정도의 리턴 로우가 발생할 것이라는 것을 예측할 수 있다. 통계 정보만 정확하다면 이들 값도 상당히 정확하다고 보면 된다.
Execution Plan을제대로보기위해서는,
• 각 데이타베이스 사용자마다 PLAN_TABLE이 있어야 하는데, PLAN_TABLE은 오라클 버전마다 다르다. 해당 오라클 버전의 $ORACLE_HOME/rdbms/admin/utlxplan.sql을 실행하면 만들어진다.
• SQL을 실행하지 않고 Trace만 보는 방법도 있다.
• EXPLAIN PLAN’<리 스 트 1>, SQL*Plus의‘ SET AUTOTRACE TRACEONLY EXPLAIN’<리스트 2>.
• 플랜을PLAN_TABLE에서 확인할 수도 있다.
• SQL을 실행하지 않고 Trace만 보는 방법도 있다.
• EXPLAIN PLAN’<리 스 트 1>, SQL*Plus의‘ SET AUTOTRACE TRACEONLY EXPLAIN’<리스트 2>.
• 플랜을PLAN_TABLE에서 확인할 수도 있다.
Oracle8i Database 이전까진 Plan_Table에서 직접 선택하고, Oracle8i Database 이상부터는 Plan_Table에서 직접 선택하거나 $ORACLE_HOME/rdbms/admin 위치에서 utxpls.sql(Serial Plan) 또는 utlxplp.sql(Parallel Plan) 스크립트를 실행하면 된다. Oracle9i Database 이전에서는 utxpls.sql, utlxplp.sql 외에‘select * from table(dbms_xplan.display);’


Cached Execution Plan(V$SQL_PLAN)
Explain Plan으로 보는 플랜과 실제 실행시 플랜이 다를 수 있다. 이는 Explain Plan은단지SQL 문장에 대한 구조적인 분석하에 예상 플랜을 만들어내기 때문이다. 예를 들어, ‘select * from emp where empno = :B1’의 SQL 문장을 실행한다고 생각해 보자.
Empno가 인덱스가 설정되어 있고 Character 타입으로 되어 있으며, 인덱스를 이용하는 것이 효과적이라고 가정하면 Explain plan은 Empno의 인덱스를 이용해서 풀릴 것이다. 그러나 실제 실행시 바인드 변수인 ‘:B1’에Character 타입이 아니라 Number 타입으로 바인드 되었다면 인덱스를 이용할 수 없는 것이다. 또한 Oracle9i Database의 Bind Peeking과 같은 기능은 처음 바인딩되는 상수에 의해 플랜을 결정하는데, 이 방식에 의해서도 그러한 상황이 있을 수 있다.
이와 같이 Explain Plan을 보는 것과 실제 예측 실행시간이 너무 차이가 난다면 Runtime Plan을 확인해 볼 필요가 있다. Oracle9i Database부터 V$SQL_PLAN의 성능뷰를 제공하며, 현재 캐쉬화 되어 있는 SQL 문장들에 대한 Runtime Plan을 확인해 볼 수 있다. V$SQL_PLAN은PLAN_TABLE과 칼럼 항목이 거의 같다.
SELECT hash_value, (select sql_text from v$sql s where s.hash_value = p.hash_value and
s.address = p.address and rownum <= 1), child_number,ID ,PARENT_ID , LPAD( ‘
‘,2*(depth))||OPERATION||DECODE(OTHER_TAG,NULL,’’,’*’)|| DECODE(OPTIONS,NULL,’’,’
( ‘||OPTIONS||’)’)||DECODE(OBJECT_NAME,NULL,’’,’OF ‘’’||OBJECT_NAME||’’’’)||
DECODE(OBJECT#,NULL,’’,’(Obj#’||TO_CHAR(OBJECT#)||’)’)||DECODE(ID,0,DECODE(OPTIMIZER,
NULL,’’,’Optimizer=’||OPTIMIZER))||DECODE(COST,NULL,’’,’
(Cost=’||COST||DECODE(CARDINALITY,NULL,’’,’Card=’||CARDINALITY)||DECODE(BYTES,NULL,’’,’
Bytes=’||BYTES)||’)’) SQLPLAN,OBJECT_NODE, PARTITION_START ,PARTITION_STOP,
PARTITION_ID, CPU_COST, IO_COST, TEMP_SPACE, DISTRIBUTION, OTHER
ACCESS_PREDICATES , FILTER_PREDICATES FROM v$sql_plan p
START WITH ID=0 and hash_value = [XXXXXXXXXX]
CONNECT BY PRIOR ID=PARENT_ID AND
PRIOR hash_value=hash_value AND
PRIOR child_number=child_number
ORDER BY hash_value,child_number,ID,POSITION
s.address = p.address and rownum <= 1), child_number,ID ,PARENT_ID , LPAD( ‘
‘,2*(depth))||OPERATION||DECODE(OTHER_TAG,NULL,’’,’*’)|| DECODE(OPTIONS,NULL,’’,’
( ‘||OPTIONS||’)’)||DECODE(OBJECT_NAME,NULL,’’,’OF ‘’’||OBJECT_NAME||’’’’)||
DECODE(OBJECT#,NULL,’’,’(Obj#’||TO_CHAR(OBJECT#)||’)’)||DECODE(ID,0,DECODE(OPTIMIZER,
NULL,’’,’Optimizer=’||OPTIMIZER))||DECODE(COST,NULL,’’,’
(Cost=’||COST||DECODE(CARDINALITY,NULL,’’,’Card=’||CARDINALITY)||DECODE(BYTES,NULL,’’,’
Bytes=’||BYTES)||’)’) SQLPLAN,OBJECT_NODE, PARTITION_START ,PARTITION_STOP,
PARTITION_ID, CPU_COST, IO_COST, TEMP_SPACE, DISTRIBUTION, OTHER
ACCESS_PREDICATES , FILTER_PREDICATES FROM v$sql_plan p
START WITH ID=0 and hash_value = [XXXXXXXXXX]
CONNECT BY PRIOR ID=PARENT_ID AND
PRIOR hash_value=hash_value AND
PRIOR child_number=child_number
ORDER BY hash_value,child_number,ID,POSITION
SQL_TRACE와TKPROF를 이용한 SQL 튜닝
SQL_TRACE 또는 10046 Trace Enable/Disable
SQL_TRACE는 애플리케이션이 SQL 문장들을 처리하는 과정을 Trace로 남기게 하는 기능이다. 10046 Trace 기능은SQL_TRACE의 기능에 추가적인 정보를 기록한다. 레벨1은SQL_TRACE 기능과같으며, 레벨4는바인드 변수 정보, 레벨8은Wait Event 정보, 레벨12는 바인드 변수 정보와 Wait Event 정보를 같이 보여준다.
주의할 점은 Trace를 On 했으면 반드시 모니터링 후 Off 해야 한다는 것이다. 그렇지않을경우Disk Full이 발생할 수 있으므로 반드시 주의해야 한다. Trace는init.ora의 user_dump_dest에서 지정된 곳에 생성된다.
• 인스턴스 레벨 : init.ora 파라미터 이용
sql_trace = {TRUE | FALSE} 또는 event = “10046 trace name context forever, level {1|4|8|12}” • 세션 레벨 : SQL*Plus 또는 애플리케이션 루틴 내
ALTER SESSION SET SQL_TRACE = {True|False};
또는10046 Trace On
alter session set events ‘10046 trace name context forever, level {1|4|8|12}’;
10046 Trace Off
alter session set events ‘10046 trace name context off’;
또는
EXECUTE dbms_session.set_sql_trace({True|False});
또는
EXECUTE dbms_system.set_sql_trace_in_session(session_id, serial_id, {True|False});
또는10046 Trace On
alter session set events ‘10046 trace name context forever, level {1|4|8|12}’;
10046 Trace Off
alter session set events ‘10046 trace name context off’;
또는
EXECUTE dbms_session.set_sql_trace({True|False});
또는
EXECUTE dbms_system.set_sql_trace_in_session(session_id, serial_id, {True|False});
Execution Plan 보기(SQL_TRACE,10046 Trace와 TKPROF) 실행 예(Oracle9i Database)
Oracle9i Database Release 2(9.2.x)부터는 튜닝 대상이 어느 곳인지(플랜상의 스텝) 판단하기 쉽게 획기적으로 개선되어, 초보자도 튜닝 대상을 쉽게 찾을 수 있다. 또한 사용자가 SQL 문장을 실행해서 결과 값을 받는 서비스 타임은‘DB 실행시간 + 대기시간’이다. Oracle9i Database부터는 SQL TRACE의 레벨에 따라 Wait 정보의 요약 정보도 같이 보여주므로 어느 곳에 병목 현상이 있는지 판단하기 쉬워졌다. 다음은Oracle9i Database Release2(9.2.x)부터개선된사항이다<리스트3>.
• 10046 Trace 레벨에 따라 Wait(레벨 8, 레벨12일경우) 정보도 표시. 각로우소스(플랜상의 스텝)마다 Statistics 표시
• Oracle9i Database에서는 time=xxxxxxxxxx 정보가 1/1000000초 단위로 나타난다. Oracle8i Database까지는 1/100초였다.
• Runtime Plan & TKPROF 실행시 플랜 주의. TKPROF …. EXPLAIN=xxxx/yyyy일 경우 플랜이 2개(Runtime Plan & Tkprof 실행 시점의 플랜)
• Oracle9i Database에서는 time=xxxxxxxxxx 정보가 1/1000000초 단위로 나타난다. Oracle8i Database까지는 1/100초였다.
• Runtime Plan & TKPROF 실행시 플랜 주의. TKPROF …. EXPLAIN=xxxx/yyyy일 경우 플랜이 2개(Runtime Plan & Tkprof 실행 시점의 플랜)

TKPROF 아웃풋의 로우 값의 버전별 변화
TKPROF의아웃풋형태가Oracle8i Database 이전까지는테이블 또는 인덱스를 찾아 들어간 로우수를 나타내며, Oracle8i Database서 부터 로우값은 필터링되어 리턴된 로우 수를 나타낸다. TKPROF 아웃풋에 로우 값이 0으로 나오는 경우는 해당 SQL 문장의 커서가 종료되기 전에 Trace가 종료되었거나 끊긴 경우이다. Runtime Plan은 커서가 종료되는 시점에 기록되므로 이 값이 0으로 나올 수 있다.

Oracle Database 10g의 튜닝 관련 신기능
Oracle Database 10g에서 튜닝 기능은 더욱 개선, 강화 되었다.
• 자동 성능 진단과 튜닝
Oracle Database 10g부터는 자가관리(self-management) 기능이 강화되었으며 , Automatic Statistics Collection, Automatic Database Diagnostic Monitoring(ADDM), Automatic SQL 튜닝과 같은 기능을 튜닝에 이용할 수 있다. Automatic Workload Repository(AWR)는셀프튜닝과 문제진단을 목적으로 성능 정보를 수집하고 처리하고 유지한다.
Automatic Database Diagnostic Monitor(ADDM)는AWR에 수집된 정보를 주기적으로 분석하고 오라클 시스템에 대한 문제의 원인을 진단하고 권장사항을 제공한다.
Oracle SQL Tuning Advisor는 SQL 문장의 최적화를 위해 빠르고 효과적인 방법을 제공한다. 내부적으로DBMS_SQLTUNE 패키지를 제공하며, 사람이 직접 하던 튜닝을 이제는 Oracle SQL Tuning Advisor의 기능을 이용해 문제의 원인을 상세하게 찾아내고 개선안을 얻을 수 있으며, 개선안을 수용하면 같은SQL 문장이 실행되었을 경우 튜닝된 결과로 플랜이 처리된다.
• Application End to End Tracing
Application End to End Tracing 기능은 클라이언트 식별자(Login ID), 서비스명(Application Group), 모듈명 또는 액션명으로 시스템 자원을 과다하게 사용하는 SQL 문장과 같은 워크로드의 원인을 찾을 수 있도록 해주는 유용한 기능이다. 즉 멀티티어 환경에서의 성능 디버깅을 쉽게 할 수 있는 기능이다.
• trcsess 유틸리티
trcsess는 커맨드라인 유틸리티로, 특정 검색조건에 해당하는 내용을 원하는여러Trace 파일에서 통합해서 한 파일로 만들어 준다. AP 서버를 두고 있는 분산 트랜잭션에서 여러AP 서버의 Trace에 분산되어 있는 Trace 정보에서 원하는 검색조건인 클라이언트 식별자, 서비스명, 모듈명 또는 액션명 등으로 찾아볼 수 있다. Application End to End Tracing의 기능에 의해 여러 파일에 흩어져 있는 Trace 내용을 모으는 데 유용하다.
• Automatic Optimizer Statistics Collection
각 오브젝트들에 대한 옵티마이저 통계정보를 자동으로 수집한다. 통계정보가 맞지 않거나 없는 경우에 자동으로 통계정보를 수집할 수 있다. DBA는 어떤 오브젝트에 대해서 통계정보를 실행해야 되는지, 어떤 통계정보가 맞지 않는지에 대해서 신경을 쓰지 않아도 되며, 직접 실행할 필요도 없다. 옵티마이저 통계정보는 GATHER_STATS_JOB로 자동으로 수집할 수 있으며, DB를 생성하거나 업그레이드할 때 자동으로 설정된다(디폴트). 이 기능은 Missing Statistics(통계정보가 없음) 또는 Stale Statistics(대량의 데이타
로딩 등에 의해 로우들이 10% 이상 변경된 경우)인 경우에 이들 오브젝트들을 관리하고 이들 오브젝트에 대해서 자동으로 수집한다. 수집 시기도 시스템 자원이 한가한 새벽시간에 운영된다.
지금까지 2회에 걸쳐 Oracle Optimizer의 원리 이해를 기반으로SQL과 애플리케이션의 튜닝 방법에 대해서 설명하였다. 애플리케이션 튜닝 부분은 자세히 다루지는 않았지만, 이번 기회에 Oracle Optimizer의 원리를 이해하고, SQL 튜닝기법을 활용하여 시스템의 안정적인 개발 및 운영에 도움이 되었으면 하는 바람이다.
피드 구독하기:
덧글 (Atom)
-
Forms Delphi Applications without Forms? From: bpeck@prairienet.org (Bob Peck) You bet! First, select File|New Project and choos...
-
<자료형(data types)> 단순형 문자열형 구조형 포인터형 가변형 정수형 문자형 대수형 열거형 범위형 실수형 단문자열형 장문자열형 광포(Wide) 문자열형 배열형 레코드형 집합형 무...
-
[팁] 프로젝트의 실행파일을 UPX로 압축하는 메뉴추가하기 양병규 (bkyang) 2001-11-20 오후 3:22:37 카테고리:강좌 2902회 조회 첨부파일 다운로드 3_upx.exe 델파이의 Tools메뉴에 upx를 추가하고 Pa...

